谷歌BERT遭遇对手,微软UniLMAI突破大量文本处理瓶颈
时间:2019-10-17 来源:互联网 浏览量:

编 | 云鹏
导语:它已经掌握了28996个词汇,但它还要学习更多。
智东西10月17日消息,去年10月谷歌发布的BERT模型已经在阅读理解测试中全面超越人类,今天微软的UniLM模型将这一领域的研究推向了新的高度。
微软近日推出的UniLM AI训练模型通过改变传统AI系统学习方式,成功实现单向预测,突破了自然语言处理中大量文本修改的瓶颈。
一、改变双向预测方式
语言模型预训练(Language model pretraining)是一种机器语言处理技术,它通过依据文本预测词汇的方式,教会机器学习系统(machine learning systems)如何把文本情景化地表述出来。它代表了自然语言处理(natural language processing)领域的最新突破。
目前,像谷歌的BERT模型,是双向预测,也就是根据左右两侧的词汇来预测,因此不适合大量文本的处理。
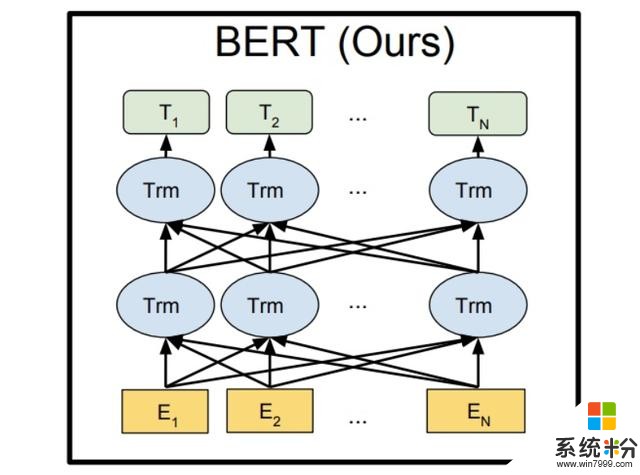
▲谷歌BERT模型
为此,微软科学家们研究出了UniLM(UNIfied pre-trained Language Model)这种新模型。该模型可以完成单向、序列到序列(sequence-to-sequence)和双向预测任务,并且可以针对自然语言的理解和生成进行微调(fine-tuned)。
微软表示它在各类常见的基础测试中都要优于BERT,并且在自然语言处理的一些测试项目中取得了该领域的最新突破。
二、“变形金刚”的威力
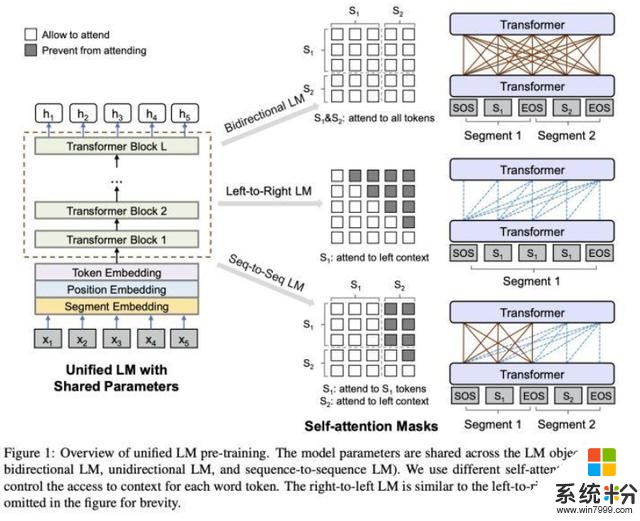
▲UniLM模型概览
UniLM模型是一个多层网络,其核心是由Transformer AI模型组成的,这些模型针对大量文本进行了共同的预训练,并针对语言建模进行了优化。
跟其他AI系统学习预测方式不同的是,Transformer AI将每个输出元素都连接到每个输入元素。它们之间的权重是可以动态调整的。
微软研究人员认为,经过预训练的UniLM与BERT类似,可以进行微调以适应各种下游任务。但是与BERT不同,UniLM可以通过一种特殊方式(using different self-attention masks),汇总不同类型语言模型的上下文。
此外,Transformer网络可以共享从历史训练中学到的数据,不仅使学习到的文本表示更加通用,也降低了对单一任务的处理难度。
三、学海无涯
微软研究人表示,UniLM通过学习英语维基百科(English Wikipedia)和开源BookCorpus的文章后,已经拥有高达28996的词汇量。并且在预培训后,UniLM的跨语言任务表现也非常好。
团队人员表示,UniLM未来发展的空间还很大,例如在“网络规模(web-scale)”的文本语料库上训练较大的模型来突破当前方法的局限性。
他们还希望让UniLM在跨语言任务中取得更大突破。
结语:自然语言处理领域的重大突破
自然语言处理,是人工智能界、计算机科学和语言学界所共同关注的重要问题,它对于实现人机间的信息交流起着重要作用。
谷歌BERT和微软的UniLM是这一领域的开拓者,后者通过单向预测突破了大量文本处理的难题,进而提升了此类AI在实际应用中的价值。
此次谷歌霸主地位被动摇,也势必将在该领域引发更加精彩的AI大战。
原文来源:Venturebeat
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软改变主意在停止支持后为Windows7黑屏bug开发免费补丁
- 2 亚马逊和微软打磨最强AI语音助手: 试邀谷歌苹果合作
- 3 Windows 10新版给力功能上线:系统瞬间清爽了
- 4微软新款Surface笔记本终于公布! 售价定为999美元
- 5微软公布Windows10X核心功能:支持UWP/Win32/PWA应用
- 6微软推超级麻将AISuphx十段水平远超人类选手
- 7微软与V社合作 WindowsVR头显将支持SteamVR
- 8微软云也是黑客的“菜” 超过3500名工程师严阵以待
- 9微软:Windows 10创造收益将继续迅猛提升
- 10iPhone面世10年 苹果利润相当于微软与谷歌总和
