什么是路由器交换算法 路由器交换算法的代码是什么
时间:2017-07-04 来源:互联网 浏览量:
今天给大家带来什么是路由器交换算法,路由器交换算法的代码是什么,让您轻松解决问题。
一.CEF特快交换基本原理路由器和交换机是基础网络中最关键的部分,路由器和交换机其最主要的目的有两个:一是如何准确的把数据包(帧)从源地址送到目标地址,二是如何更快速的送达。当然第二点的优先级要低于第一点的。为了更好的完成这两个任务,交换机和路由器经过了多年的发展其各自交换包的方法也在不断改进,其不论如何变化都是为了更好的完成这两个根本任 务。本篇的主题是讲解CEF基本原理
www.zhishiwu.com 首先,先来看一下包转发的过程。一般来说对于一个路由器会有以下三步:1. 查看这个包的目标地址是否可达2. 决定目标地址的下一跳和接口。3. 改写MAC的包头使得它可以成功的到达下一跳。
以上三步是路由器包交换的根本,到现在为止所有衍生出来的包交换方法都必须完成以上三个过程。
为了更好的理解CEF,再阐述一下另外两种比较著名的包交换方法:进程交换和快速转发
www.zhishiwu.com
进程交换
最古老的一个交换方法,被所有的平台所支持。
为了便于理解,用图来具体讲解进程交换的方式。
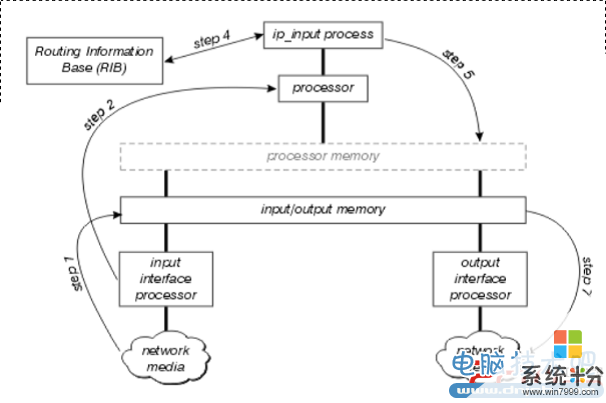 1. 接口进程(input interface processor)首先在网络中发现数据包,然后把它传递给“input/output memory”(输入输出内存)2. 接口进程创建一个接到数据的中断。在这个中断过程中,中央处理器决定这个包的类型(一般是IP),如果需要的话就把它拷贝到内存中(processor memory)。最后,处理器把这个包放在一个适当的进入队列中(process’ input queue),同时中断取消。3. 然后调度程序开始启动IP_INPUT进程 www.zhishiwu.com 4. 当IP_INPUT进程启动,它开始从RIB(路由表)中决定下一跳和外出接口,然后查找ARP缓存找到下一跳的MAC地址.(如果缓存中没有对应的地址的话将要进行ARP广播)5. IP_INPUT进程重写包的MAC地址,然后把包的放在合适端口的外出队列中。6. 把包从外出端口的外出队列中拷贝到外出端口的传输队列。7. 外出接口处理器在外出队列中发现这个包然后把这个包传输到网络当中。
1. 接口进程(input interface processor)首先在网络中发现数据包,然后把它传递给“input/output memory”(输入输出内存)2. 接口进程创建一个接到数据的中断。在这个中断过程中,中央处理器决定这个包的类型(一般是IP),如果需要的话就把它拷贝到内存中(processor memory)。最后,处理器把这个包放在一个适当的进入队列中(process’ input queue),同时中断取消。3. 然后调度程序开始启动IP_INPUT进程 www.zhishiwu.com 4. 当IP_INPUT进程启动,它开始从RIB(路由表)中决定下一跳和外出接口,然后查找ARP缓存找到下一跳的MAC地址.(如果缓存中没有对应的地址的话将要进行ARP广播)5. IP_INPUT进程重写包的MAC地址,然后把包的放在合适端口的外出队列中。6. 把包从外出端口的外出队列中拷贝到外出端口的传输队列。7. 外出接口处理器在外出队列中发现这个包然后把这个包传输到网络当中。紧接着再来看第二种重要的交换方法:快速交换
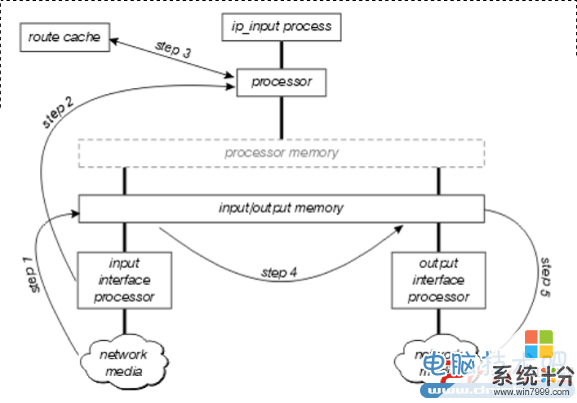 1. 接口处理器发现网络中的包,然后把包传递给input/output memory2. 接口处理器创建一个接收中断。在这个中断的过程中,中央处理器决定包的类型(假定是IP类型),然后立即开始交换这个包。3. 处理器开始搜索路由缓存来决定是否这个包的目的地址可达,外出接口是什么以及这个包需要怎么改写MAC才能可达下一跳。4. 然后把包拷贝到外出端口的传输队列或者外出队列(这个根据不同厂商的不同而不同)。这时接收中断取消,处理器继续做刚才没有做完的任务。5. 外出接口处理器发现数据包在传输队列,然后把包传输到网络中。
1. 接口处理器发现网络中的包,然后把包传递给input/output memory2. 接口处理器创建一个接收中断。在这个中断的过程中,中央处理器决定包的类型(假定是IP类型),然后立即开始交换这个包。3. 处理器开始搜索路由缓存来决定是否这个包的目的地址可达,外出接口是什么以及这个包需要怎么改写MAC才能可达下一跳。4. 然后把包拷贝到外出端口的传输队列或者外出队列(这个根据不同厂商的不同而不同)。这时接收中断取消,处理器继续做刚才没有做完的任务。5. 外出接口处理器发现数据包在传输队列,然后把包传输到网络中。现在,回过头来观察对比一下这两个交换方式究竟有什么不同之处。
在讲二者区别之前,先插一个概念。
到目前为止,包交换的方法有N种,其重要的有两类,第一个就是进程交换,而第二类名字叫做“Interrupt Context Switching”,而这第二类中包含的交换方法有“快速交换”、我们熟知的CEF,还有 一个是Optimum交换。
在阅读下面的文字之前一定要把这个层次关系搞明白。
所谓进程交换,顾名思义,就是要创建进程,我们知道处理器在工作的时候是按照schedule(计划)进行工作的,而进程交换就是这样的,它会创建一个名 为“IP_INPUT”(假设讨论的是IP包),然后放入到处理器的SCHEDULE中等待,什么时候排到了什么时候执行这个进程。发现什么问题了吗?排 队这样的规则从设计的角度来说是很不错的,但是对于包交换来说就有一些拖沓,假设目前处理器有其他的工作要做,这个时候其创立的进程“IP_INPUT” 就必须在SCHEDULE中等着,不能执行,只有当排到的时候才能执行,这样显然是浪费时间的。
相比之下,Interrupt Context Switching就要“霸道”很多,注意这个“INTERRUPT”,注意我的黑体字,这个交换方式跟进程交换的区别就是“不排队”,只要有包过来就先 处理它,等它处理完了,处理器再回去干它SCHEDULE中的工作。
以上就是进程交换和Interrupt Context Switching的不同点之一。
另外一个不同点,如果你看过我上一篇文章的话,你可能有印象,就是增加了“缓存”,处理器在查找目标地址可达、下一跳这些信息的时候不是直接去查找路由表而是去查找缓存。这也是不同点之二。
第一个不同点让交换增速不少,那么第二点不同的作用又是什么呢?“缓存到底有什么用?”
对于Interrupt Context Switching这一类交换方式来说有三种不同的交换方法刚才已经介绍过了,他们是
Fast Switching
Optimum Switching
Cisco Express Forwarding
这三种方法的主要区别就体现于其构建缓存方法的差别上,而正是由于这种差别才导致他们某些特性的不同。
先从最基础的快速交换(Fast Switching)谈起
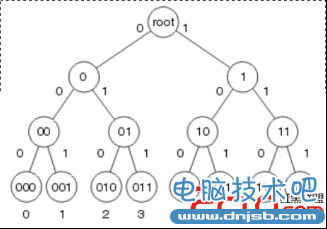 如上图,这是一颗二叉树,这也是快速交换中的缓存数据结构,快速交换把外出接口信息和需要重写的MAC地址放到二叉树中相应的节点上,而需要转发到的目的地址就是二叉树上节点所代表的地址。那么这样的遍历是如何进行呢?比如给出一个数是4,转化成二进制100,查找从最高位开始,从root节点出发,第一步走向root的右子树,因为100的第一位(最高位)是1,而后走向左子树,再继续向左子树方向走,这个时候就查找到100了。如果这是一个真实的IPV4地址的话,最多需要32次查找便可以找到我们需要的网段是不是很快呢?鉴于IPV4地址的长度原因,快速交换的二叉树深度是32。以上就是快速交换高速缓存中的数据结构,以及查找方法,下面我们看看由此而产生的一些特性,并且找出它的不足。1、由于这个快速缓存是凭空建立的,并没有和路由表以及MAC缓存建立联系,所以当我们想应用快速交换进行查找的时候必须要先进行一次完整的过程交换。2、由于在快速缓存中一个节点对应着一个地址,而且没有指针可以链接各个节点,所以无法实现递归查询。不过这并不影响路由器使用递归查询,因为当每一个新的数据包进来之后都要进行一次进程交换,其间已经完成了递归查询。3、由于节点信息的建立是由路由表和ARP缓存而来,当路由表或者是ARP缓存刷新时,对应的节点应该无效,这时就必须重新建立一个二叉树,在这个过程中 快速交换是无法使用的,只能用传统的进程交换,试想如果这是一个非常大的网络,其网络状态不断变化,这将会大大影响快速交换的效率。通过介绍快速交换,现在解决了一个问题,为什么高速缓存的建立要比直接查找路由表要快速。但是通过分析发现它也不是尽善尽美的,有没有更好的办法呢?我们看下一个交换方式Optimum Switching
如上图,这是一颗二叉树,这也是快速交换中的缓存数据结构,快速交换把外出接口信息和需要重写的MAC地址放到二叉树中相应的节点上,而需要转发到的目的地址就是二叉树上节点所代表的地址。那么这样的遍历是如何进行呢?比如给出一个数是4,转化成二进制100,查找从最高位开始,从root节点出发,第一步走向root的右子树,因为100的第一位(最高位)是1,而后走向左子树,再继续向左子树方向走,这个时候就查找到100了。如果这是一个真实的IPV4地址的话,最多需要32次查找便可以找到我们需要的网段是不是很快呢?鉴于IPV4地址的长度原因,快速交换的二叉树深度是32。以上就是快速交换高速缓存中的数据结构,以及查找方法,下面我们看看由此而产生的一些特性,并且找出它的不足。1、由于这个快速缓存是凭空建立的,并没有和路由表以及MAC缓存建立联系,所以当我们想应用快速交换进行查找的时候必须要先进行一次完整的过程交换。2、由于在快速缓存中一个节点对应着一个地址,而且没有指针可以链接各个节点,所以无法实现递归查询。不过这并不影响路由器使用递归查询,因为当每一个新的数据包进来之后都要进行一次进程交换,其间已经完成了递归查询。3、由于节点信息的建立是由路由表和ARP缓存而来,当路由表或者是ARP缓存刷新时,对应的节点应该无效,这时就必须重新建立一个二叉树,在这个过程中 快速交换是无法使用的,只能用传统的进程交换,试想如果这是一个非常大的网络,其网络状态不断变化,这将会大大影响快速交换的效率。通过介绍快速交换,现在解决了一个问题,为什么高速缓存的建立要比直接查找路由表要快速。但是通过分析发现它也不是尽善尽美的,有没有更好的办法呢?我们看下一个交换方式Optimum Switching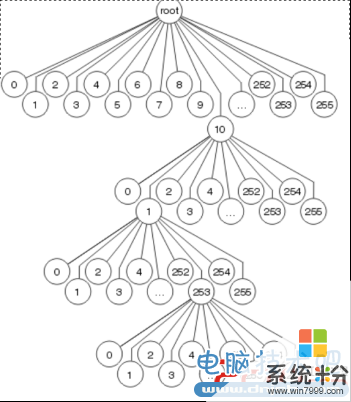
快一点!更快一点!二叉树的构想是好的,但是它最多可能查询32级还是显得有些多,有没有更快的呢?Optimum Switching主要就是改进了快速交换的数据结构,它重新构造了一个多枝(256-way mtree),如图所示,这样一来它最多只需要四次查找就可以达到目的,而一般来说只需要一到三次查找就可以了。这是一个不错的构想,但对于快速交换的其他方面并没有进行改进,只能算作快速交换的一个升级版本,不过它却起到了承上启下的作用。接下来我们看看具有革命性的CEF!CEF是在快速交换和Optimum Switching的基础上发展起来的第三代基于 Interrupt Context Switching的交换方式,它很好的克服了前两种方法带来的弊端。 二,CEF提供了以下优点:1• 改进的性能,CEF是小于快速切换路由缓存CPU密集型。更多的CPU处理能力,可专用于第3层服务,如服务质量(QoS)和加密。2• 可扩展性,CEF在每个线卡提供了充分的交换容量时,分布式CEF(dCEF)模式是积极的。3• 弹性的CEF提供了前所未有的水平在大型动态网络的一致性和稳定性的开关。4• 虽然您可以使用CEF在任何一个网络的一部分,它是专为高性能,高弹性的第3层IP骨干交换。例如:下图显示了CEF正在运行的Cisco 12000系列千兆位交换路由器在网络的核心汇聚点(GSRS)交通水平,密度和性能是至关重要的。
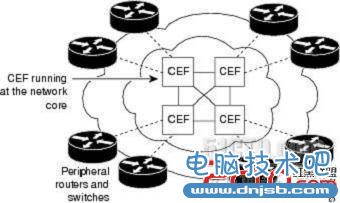 在一个典型的高容量的互联网服务供应商的环境,在支持的网络链接到Cisco 7500系列路由器或其他接驳设备的核心汇聚设备的思科12012职系架构检讨。CEF在这些平台在网络核心提供所需的性能和可扩展性,以应对持续增长和不断增加的网络流量。CEF是一种分布式的交换机制,与安装在路由器的接口卡和带宽的线性扩展。5• CEF有两个组件一个叫做FIB(Forwarding Information Base)另一个叫做邻接表(Adjacency Table),这两个表包括了所有的转发信息,而这些转发信息是根据路由表和ARP来构造的。其中FIB表可以看作是RIB(Router Information Base)的镜像,它们是一一对应的,这也就是说相较于快速转发CEF不需要去维护高速缓存,当路由表变化的时候FIB表也会发生变化。邻接表的作用是建 立二层信息表,当一个邻居被发现(从ARP表中)并且获知其二层信息之后,邻接表就把这个信息写入表中并且与第三层的FIB表提前进行关联。
在一个典型的高容量的互联网服务供应商的环境,在支持的网络链接到Cisco 7500系列路由器或其他接驳设备的核心汇聚设备的思科12012职系架构检讨。CEF在这些平台在网络核心提供所需的性能和可扩展性,以应对持续增长和不断增加的网络流量。CEF是一种分布式的交换机制,与安装在路由器的接口卡和带宽的线性扩展。5• CEF有两个组件一个叫做FIB(Forwarding Information Base)另一个叫做邻接表(Adjacency Table),这两个表包括了所有的转发信息,而这些转发信息是根据路由表和ARP来构造的。其中FIB表可以看作是RIB(Router Information Base)的镜像,它们是一一对应的,这也就是说相较于快速转发CEF不需要去维护高速缓存,当路由表变化的时候FIB表也会发生变化。邻接表的作用是建 立二层信息表,当一个邻居被发现(从ARP表中)并且获知其二层信息之后,邻接表就把这个信息写入表中并且与第三层的FIB表提前进行关联。为了更快速的找到目的地址可达性信息,它依旧采用了Optimum Switching的mtree方式,唯一有区别的是CEF构建的mtree节点中并没有包含外出接口MAC地址这些信息,而是变成了一个指针,指向一个单独建立的表。CEF采用一个4级每级256条通道结构的转发表来指明转发条目的位置,转发表有next hop等信息,涵盖了整个IPv4的地址范围,并有指针指向另一个邻接表。转发条目(MAC地址之类)都存储在一个单独的邻接表上。
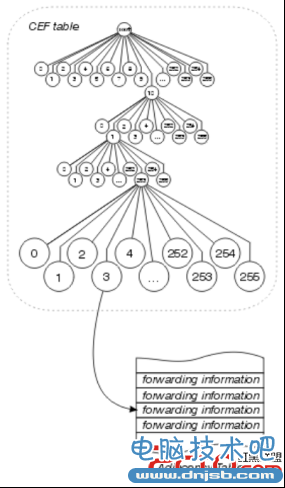 如果以上步骤完成之后,那么当一个数据包入站之后在进行目的地址的查询之后便可以顺利的进行转发,大大节省了CPU的资源,并且可以完全抛弃进程交换。6•CEF简化了查询的步骤,提高了单位时间的工作效率。而且从整体上来看,路由信息和转发信息是分离的,数据包的转发只根据转发信息而不用参照路由信息,可以充分利用专用硬件的功能来达到线速转发,CEF相较于前两种交换方式的改进主要在于对路由信息的“独立化”,而这种独立化带来的优势就是可以进行“预查找”,而不必等到数据包到来是才进行查找。而不受路由变化或者其他因素的干扰,保证了转发的高速高效。这就是CEF能够提速的最关键因素。 三。CEF操作在路由器初始化时,会根据路由器软件配置中的信息构建一张路由选择表(如静态路由、直连路由,以及通过路由选择协议交换动态学习到的路由)。在构建了路由选择表之后,CPU自动创建FIB和邻接表。FIB 和邻近表显示了按照最佳转发方式进行的出现在路由选择表中的数据。与基于通信流的流缓存不同,cEF表是基于网络拓扑。当一个分组进入交换机时,交换机的第3层转发引擎ASIC根据目的网络和最详细的网络掩码澎于最长匹配查找。并且不涉及除路由选择表和预先建立的FIB 表之外的任何软件。此外,一旦路由选择表中发生了变化,所有的cEF 表会立即更新。这使得这个方法是高效的,缓存不会由于路由翻动而无效。CEF 更加适应网络拓扑的变化。CEF在软件形式上实现了路由和交换功能的分离,而并不意味着路由器物理结构上的分离,所以它也可以在一些多层交换机和低端的路由器上实施。它的高速表现在以下方面:
如果以上步骤完成之后,那么当一个数据包入站之后在进行目的地址的查询之后便可以顺利的进行转发,大大节省了CPU的资源,并且可以完全抛弃进程交换。6•CEF简化了查询的步骤,提高了单位时间的工作效率。而且从整体上来看,路由信息和转发信息是分离的,数据包的转发只根据转发信息而不用参照路由信息,可以充分利用专用硬件的功能来达到线速转发,CEF相较于前两种交换方式的改进主要在于对路由信息的“独立化”,而这种独立化带来的优势就是可以进行“预查找”,而不必等到数据包到来是才进行查找。而不受路由变化或者其他因素的干扰,保证了转发的高速高效。这就是CEF能够提速的最关键因素。 三。CEF操作在路由器初始化时,会根据路由器软件配置中的信息构建一张路由选择表(如静态路由、直连路由,以及通过路由选择协议交换动态学习到的路由)。在构建了路由选择表之后,CPU自动创建FIB和邻接表。FIB 和邻近表显示了按照最佳转发方式进行的出现在路由选择表中的数据。与基于通信流的流缓存不同,cEF表是基于网络拓扑。当一个分组进入交换机时,交换机的第3层转发引擎ASIC根据目的网络和最详细的网络掩码澎于最长匹配查找。并且不涉及除路由选择表和预先建立的FIB 表之外的任何软件。此外,一旦路由选择表中发生了变化,所有的cEF 表会立即更新。这使得这个方法是高效的,缓存不会由于路由翻动而无效。CEF 更加适应网络拓扑的变化。CEF在软件形式上实现了路由和交换功能的分离,而并不意味着路由器物理结构上的分离,所以它也可以在一些多层交换机和低端的路由器上实施。它的高速表现在以下方面:1>在查询方式上简化了步骤,提高了速度;
2>在分离了路由和转发功能。 CEF的讲解到此为止了,对于CEF,之所以说他是革命性的,不仅仅是因为其改进了查找的方式,而是因为它还有很多其他的特征,比如在负载均衡方面它相 较于其他的交换方式也有很大的进步;如果我们要启用MPLS,必须使用CEF,因为只有CEF能够在转发的包中加入标签等等。总 结一下:回顾整个路由器包交换的发展,我们可以把它分成两类,四种方法。两类是:Process Switching类和Interrupt Context Switching类。四种方法:进程交换属于Process Switching,其他的三种 Fast Switching,Optimum Switching,CEF(Cisco Express Forwarding)属于Interrupt Context Switching
以上就是什么是路由器交换算法,路由器交换算法的代码是什么教程,希望本文中能帮您解决问题。
我要分享:
相关教程
- ·路由器怎样当做交换机 路由器当做交换机的方法
- ·交换机如何接二级路由器 交换机接二级路由器使用的方法有哪些
- ·CISCO交换机怎么配置静态路由 CISCO交换机配置静态路由有什么方法
- ·交换机下怎样接无线路由器? 交换机下接无线路由器的方法有哪些?
- ·交换机接无线路由器如何设置 交换机接无线路由器设置的方法有哪些
- ·h3c交换机是什么?h3c交换机如何配置? h3c交换机是什么?h3c交换机配置的方法?
- ·硬盘序列号怎么修改 如何修改硬盘码
- ·电脑软件播放没有声音 电脑播放视频没有声音怎么解决
- ·u盘的两个分区怎么合并 U盘被分区后怎么恢复合并
- ·excel输入数字显示对应内容 Excel中如何将数字转换为文本显示
电脑软件教程推荐
- 1 电脑搜狗输入法设置五笔输入 电脑搜狗输入法五笔设置方法
- 2 excel表格一键填充 Excel中如何实现批量填充数据
- 3 电脑键盘可以打五笔吗 五笔输入法快速打字技巧
- 4怎么快速返回桌面快捷键 电脑桌面快速回到桌面的操作步骤
- 5iphonex电池怎么显示百分比 iPhoneX电池百分比显示设置步骤
- 6万能钥匙电脑怎么连接wifi 电脑如何使用WiFi万能钥匙
- 7电脑怎么打开键盘输入 电脑虚拟键盘打开方法详解
- 8共享打印机无法找到核心驱动程序包 如何解决连接共享打印机时找不到驱动程序的问题
- 9电脑无线网总是自动断开 无线wifi频繁自动断网怎么解决
- 10word怎么显示换行符号 Word如何隐藏换行符
电脑软件热门教程
- 1 真三国无双3修改器下载,353修改器如何用 真三国无双3修改器下载,353修改器用的方法
- 2 魅族手机flyme 安卓4.4版本怎么安装supersu 魅族手机flyme 安卓4.4版本安装supersu的方法
- 3 让非管理组成员也能创建原始套接字的步骤 怎么让非管理组成员也能创建原始套接字
- 4教你怎么用普通软件做成动漫剪辑。 教你用普通软件做成动漫剪辑的方法。
- 5智能网络电视如何联网收看各类网络视频 智能网络电视联网收看各类网络视频的方法
- 6打印机出现两个红灯交错闪怎么解决 如何应对打印机出现两个红灯交错闪
- 7网游是否可以赚钱 玩网游是否可以给我们的收入得到提高
- 8steam游戏如何卸载 steam如何彻底卸载游戏
- 9点心闹钟如何删除语音备忘录 点心闹钟删除语音备忘录怎么操作
- 10电脑怎么进行碎片整理 电脑进行碎片整理的方法
