微软研究院发布开放数据项目,公开内部研究数据集
时间:2018-06-26 来源:互联网 浏览量:
编者按:微软技术院士、图灵奖得主Jim Gray提出了科研的第四范式——数据科学在科学研究中的普遍性。随着大数据时代的到来,除了计算机科学领域,其它跨学科与跨领域的研究也同样对高质量的数据集存在大量需求。为此,微软研究院发布了开放数据项目,并对外开放了部分内部研究数据集,希望促进全球学术界和产业界的广泛合作。本文翻译自微软研究院博客“Announcing Microsoft Research Open Data –Datasets by Microsoft Research now available in the cloud”,有删减。
近期,微软对外发布了微软研究院开放数据项目(Microsoft Research Open Data),这套新的云数据资料库囊括了微软多年以来在已发表的研究中所使用的数据管理和研究成果。
我们的目标是为研究人员与合作者提供一个简单便捷的平台,来共享数据集和相关研究技术与工具。微软研究院开放数据项目旨在简化对这些数据集的访问流程,促进使用云资源的研究人员之间的协作,实现研究资源的可复用性。
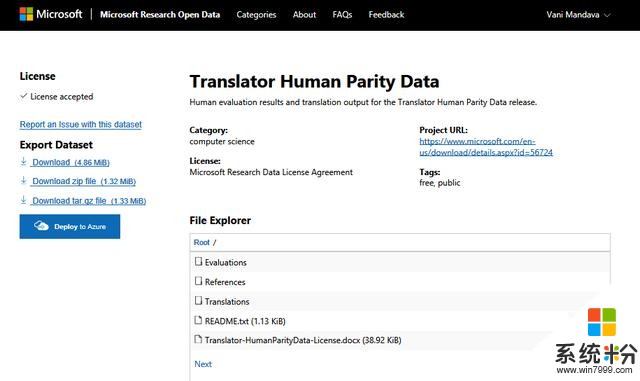
微软研究院开放数据项目中的数据集
随着全球数据总量的指数级增长,人们普遍认为在2025年数据总量就将超150ZB。人们已经认识到应该优先处理数据,而不是依赖缓慢增长的互联网带宽迁移数据。因此我们相信,开放数据集将为学术界和产业界带来巨大的应用价值。
麻省理工学院教授Sam Madden表示“微软开放数据项目将改变大数据时代的游戏规则,能够大大减少数据共享的障碍,借助云计算的力量促进研究资源的可复用性。”
开放了哪些数据集?
微软研究院开放数据项目中的数据集根据研究领域进行分类,涵盖计算机科学、社会科学、物理学、天文学、生物学、经济学等等多个学科领域,如下图所示。
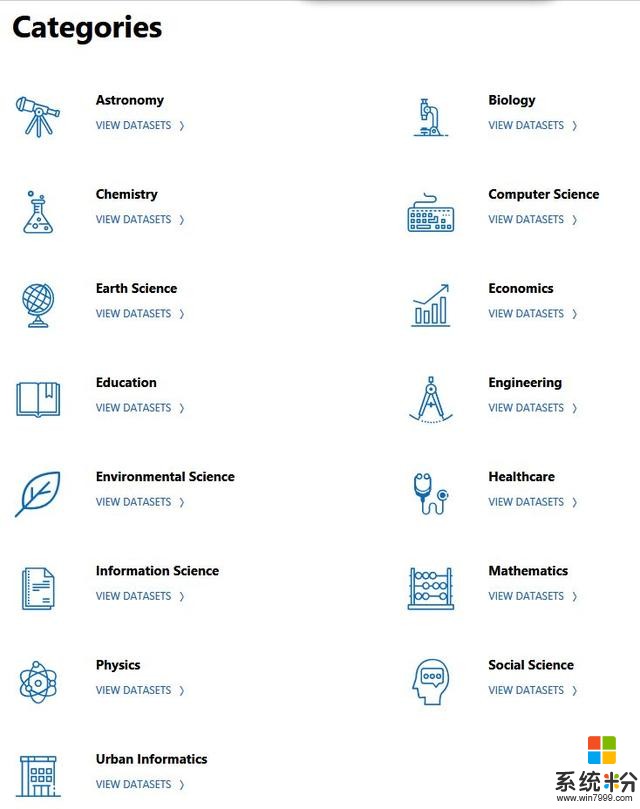
数据集中的分类
微软研究院开放数据项目尽可能达到了数据共享的最高标准,以确保数据集可发现性、可访问性、互操作性和可复用性,且整套数据资料库不包含任何个人身份信息。
目前该项目包含了数十个已开放的数据集,我们为大家介绍其中的几个精选数据集:
微软机器阅读理解(MS MARCO)
微软机器阅读理解(MS MARCO)是一个全新的用于阅读理解和问题解答的大型数据集。在MS MARCO中,所有问题都来自于真正匿名用户的搜索查询。用于推断回答的上下文语境则来自于必应搜索引擎抓取的真实Web文档。回答则由人工生成。
文件大小:469.03 MB
文件类型:json
许可协议:微软研究院数据许可协议
详细信息:
https://msropendata.com/datasets/2bda14a7-ee25-4092-8f2f-9272d48ae903
微软研究院社交媒体对话语料库
该数据集集合了从Twitter日志中提取的代表4,232个三步会话片段的12,696个Tweet ID。数据集中的每一行表示一个单独的上下文-消息-响应三元组,众包注释者在李克特量表上为上下文响应质量的评分平均为4或更高。数据已被随机分为开发数据集和测试数据集,分别包含2118和2114个三元组。该数据集仅在自然语言处理社区供学术研究之用。为了访问底层推文和相关元数据,需要调用Twitter API。
如果在研究中使用该数据集,请在文中引用以下文章:
Alessandro Sordoni, Michel Galley, Michael Auli, Chris Brockett, Yangfeng Ji, Meg Mitchell, Jian-Yun Nie, Jianfeng Gao, and Bill Dolan, A Neural Network Approach to Context-Sensitive Generation of Conversational Responses, Conference of the North American Chapter of the Association for Computational Linguistics – Human Language Technologies (NAACL-HLT 2015), June 2015.
文件大小:245.46 KB
文件类型:txt
SigmaDolphin
SigmaDolphin是2013年初在微软亚洲研究院启动的一个项目,其主要目标是建立一个具有自然语言理解和推理能力的计算机智能系统,专注于自动解题的应用,即自动解决用自然语言编写的问题(特别是数学问题)。
文件大小:11.54 MB
文件类型:json、pdf、pkl、py、txt
许可协议:微软研究院数据许可协议
详细信息:
https://msropendata.com/datasets/f0e63bb3-717a-4a53-aa79-da339b0d7992
如何获取和使用开放数据集?
现在可以访问microsoftopendata.com浏览和下载可用的数据集,或者通过自动工作流将它们直接通过Azure订阅复制到基于Azure的Data Science虚拟机上,如下图所示。
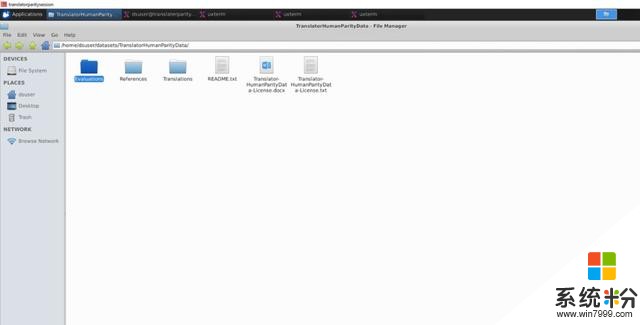
数据集可直接复制到基于Azure的Linux虚拟机上
Data Science虚拟机已经预装了许多广受研究人员与开发者欢迎的开发工具,如下图所示。
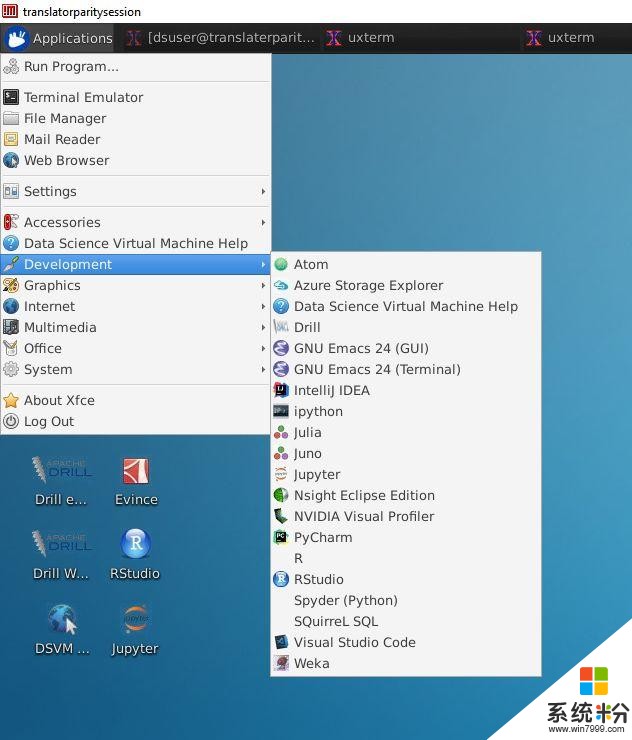
Linux Data Science虚拟机
微软研究院开放数据项目是微软各个团队、研究人员、行业合作伙伴以及学术顾问的合作成果。在未来,我们还将根据社区的反馈意见继续完善和发展这套云数据资料库。
点击阅读原文,了解项目更多详情。
你也许还想看:
,共建交流平台。来稿请寄:msraai@microsoft.com。
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软改变主意在停止支持后为Windows7黑屏bug开发免费补丁
- 2 亚马逊和微软打磨最强AI语音助手: 试邀谷歌苹果合作
- 3 Windows 10新版给力功能上线:系统瞬间清爽了
- 4微软新款Surface笔记本终于公布! 售价定为999美元
- 5微软公布Windows10X核心功能:支持UWP/Win32/PWA应用
- 6微软推超级麻将AISuphx十段水平远超人类选手
- 7微软与V社合作 WindowsVR头显将支持SteamVR
- 8微软云也是黑客的“菜” 超过3500名工程师严阵以待
- 9微软:Windows 10创造收益将继续迅猛提升
- 10iPhone面世10年 苹果利润相当于微软与谷歌总和
