人工智能算法重磅微软提出字符字体转换和神经风格转换的统一框架
时间:2018-06-17 来源:互联网 浏览量:
人工智能算法重磅微软提出字符字体转换和神经风格转换的统一框架(特约点评:人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架对于对风格统一转移提供了新的思路,这个创新点趣说人工智能必须推荐。来自网友小星的推荐!)
人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架简介:近年来,风格转换作为深度神经网络(DNNs)的一个有趣的应用已经引起了研究界越来越多的关注。根据样式类型,样式转换可以分为两类应用程序:将字符从字体转移到另一个字符的字符字体转换,以及旨在将神经图像转换为给定艺术风格的神经风格转移。字符字体转换通常涉及高频特征的变化,例如对象形状和轮廓,这使得字符字体转移比神经风格转移更困难。而且,这些字符具有清晰的语义含义,不正确的转换可能导致无意义的字符。与字符字体转换不同,神经风格转移主要是关于纹理的转移,其中源图像和目标图像通常共享物体形状和轮廓等高频特征,即内容保持不变。
最早的关于字符字体转换的研究通常基于人工提取的特征,例如部首和笔划[18,36,38,40]。最近,一些研究尝试自动学习基于DNN的转换,并将字符字体转换模型作为图像到图像的转换问题。通常情况下,为每个源和目标样式对建立专用模型[1],[23],使得模型难以归纳为新的样式,即需要为新样式培训附加模型。为了实现字体转换而不需要再训练,提出了一种多内容生成对抗网络(GAN),该网络可以转换目标风格中给定几个字符的英文字体的字体[4]。
最早的神经风格转移研究通常采用迭代优化机制来生成噪声图像中具有目标风格和内容的图像[11]。由于时间效率低下,为此提出了一种前馈发电机网络[15],[31]。针对传输网络提出了一组丢失,如像素丢失[13],感知丢失[15],[37]和直方图丢失[34]。最近,GANs [21],[41]的变体通过向传输网络添加鉴别器来引入,该鉴别器将对抗性损失与传输损耗相结合以产生更好的图像。然而,这些研究旨在明确地学习从内容图像到具有特定风格的图像的转换,并且学习的模型因此不能推广到新的风格。到目前为止,任意神经风格转移的工作仍然有限。
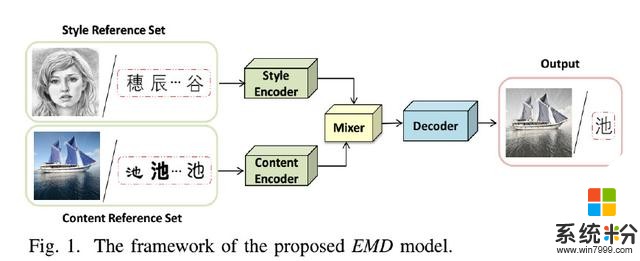
人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架贡献:在本文中,基于我们以前的工作[39],我们提出了一个统一的字体字形转换和神经风格转换的样式转换框架,使转换模型可以很好地推广到新的风格或内容。与现有的样式转换方法不同,为每对样式转换构建单独的转换网络,所提出的框架使用一小组参考图像表示每种样式或内容,并试图学习样式和内容的单独表示。然后,为了生成给定样式 - 内容组合的图像,简单地混合相应的两个表示。这种学习框架允许在多种风格之间同时进行风格转移,并且可以被视为一种特殊的“多任务”学习场景。通过独立的风格和内容表示,框架能够生成所有风格 - 内容组合的图像,并给出相应的参考集合,因此可以很好地推广到新的风格和内容。据我们所知,与我们最相似的研究是Tenenbaum和Freeman [30]提出的双线性模型,它通过矩阵分解获得了独立的样式和内容表示。但是,为了准确分解新的样式和内容,双线性模型需要详尽列举一些可能无法用于某些样式/内容的示例。如图1所示,所提出的样式传输框架,之后表示为EMD,由样式编码器,内容编码器,混合器和解码器组成。给定一个或一组参考图像,风格编码器和内容编码器分别用于从风格参考图像和内容参考图像中提取风格和内容因子。混合器然后结合相应的风格和内容表示。最后,解码器基于组合表示生成目标图像。
在这个框架下,我们分别设计了两个单独的字符字体转移网络和神经风格转移网络。对于字符字体转换,为了分离样式特征和内容特征,我们利用给定图像的样式和内容的条件依赖性,并采用双线性模型来混合这两个因素。对于神经风格转移,我们利用先前的知识,即某些层中的特征地图的统计信息可以表示风格信息,并通过统计匹配将这两个因子混合。在训练中,针对所提出的网络的每个训练样例被提供为风格内容对<Si,Cj> 其中Si和Cj分别是样式和内容参考集,每个由相应样式Si和内容Cj的r个图像组成。 对于字符字体传输,整个网络是端对端训练,加权L1损失,测量生成的图像和目标图像之间的差异。 对于神经风格转移,由于缺乏监督目标图像,我们通过比较生成图像的特征图与风格/内容参考图像的特征图来分别计算内容损失和风格损失。 因此,神经风格转移是无监督的。 而且,由于对于获得相同内容或样式的图像的困难,仅将一个样式和内容参考图像用作输入(即,r = 1)。 广泛的实验结果证明了我们的风格转移方法的有效性和鲁棒性。
我们研究的主要贡献总结如下:
•我们提出了一个统一的样式转换框架,用于字符字体转换和神经风格转换,它们学习不同的风格和内容表示。
•该框架使得传递模型可以推广到任何看不见的风格/内容,并给出几张参考图片。
•在这个框架下,我们分别设计了两个字符字体转换网络和神经风格转换网络,这些网络在实验验证中表现出了令人鼓舞的结果。
•这种学习框架允许在多种风格之间同时进行风格转换,可以被视为一种特殊的“多任务”学习场景。
人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架字符字体转移:1)数据集:为了评估所提出的具有中文字体转换任务的EMD模型,我们构建了832个字体(样式)的数据集,每个字体具有1732个常用中文字符(内容)。所有图像的大小为80 80像素。我们随机选择75%的样式和内容(即624列车样式和1299列车内容),剩下25%作为新颖的样式和内容(即208种新颖风格和433种新颖内容)。整个数据集被相应地划分为如图4所示的四个子集:D1,具有已知样式和内容的图像,D2,具有已知样式但新颖内容的图像,D3,具有已知内容但新颖样式的图像以及D4,具有已知样式和内容的图像新颖的风格和新颖的内容。训练集从D1中选择,并且分别从D1,D2,D3和D4中选择四个测试集。这四个测试集代表了不同级别的风格转移挑战。
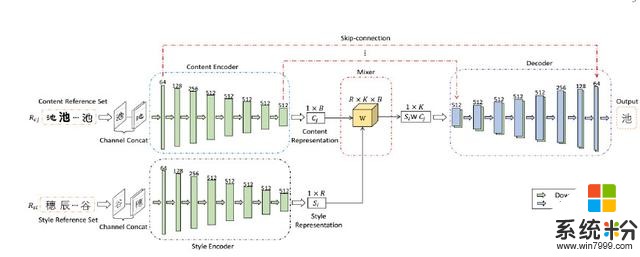
实现细节:在我们的实验中,Style Encoder和Content Encoder中卷积层的输出通道分别是C的1,2,4,8,8,8,8,8倍,其中C = 64。对于混音器,我们在实现中设置R = B = K。解码器前7个解卷积层的输出通道分别为C的8,8,8,4,2,1倍。我们将初始学习率设为0.0002,并使用Adam优化方法端到端地训练模型,直到输出稳定。
在每个实验中,我们首先从D1中随机采样具有已知内容和已知风格的Nt目标图像作为训练实例。然后,我们通过对结构的r图像进行随机采样,为每个目标图像构建两个参考集。每行代表一种样式,每列代表一种内容。目标图像由随机分散的红色“x”标记表示。目标图像的参考图像从相应的风格/内容中选择,如风格参考图像的橙色圆圈和内容参考图像的绿色圆圈所示。
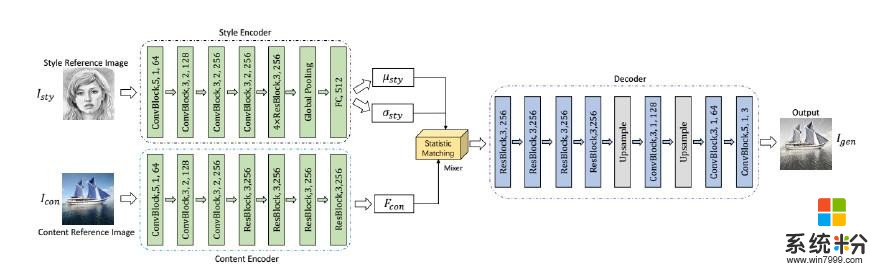
人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架:神经风格转移:1)实现细节:根据以前的研究[12] [15],我们使用MS-COCO数据集[19]作为内容图像,主要从维基百科[3]收集的绘画数据集作为样式图像。每个数据集大约包含80,000个训练样例。该模型使用Adam优化器进行训练,学习率为0.0001。批量大小设置为8个样式内容对。我们计算风格使用Relu1 2,Relu2 2,Relu3 3,Relu4 3层VGG-19和使用Relu4 1层损失内容。我们设定λc= 1,λs= 5和λtv= 1e-5。在训练过程中,我们首先将两幅图像的最小尺寸调整为512,同时保留纵横比,然后随机裁剪尺寸为256 256的区域。由于Style Encoder中完全连接图层的大小仅与滤镜数量有关,因此我们的模型可以在测试过程中应用于任何尺寸的样式/内容图像。
2)比较方法:我们将提出的神经风格转移模型与以下三种类型的基线方法进行比较:
•快速但不灵活的每种样式每种模式方法,它仅限于单一样式,不能推广到新样式。这里我们使用最先进的方法TextureNet [32]为例。 TextureNet主要是一个生成器,它将噪声变量z和内容参考图像作为输入,并生成具有目标样式/内容的图像•灵活但缓慢的基于优化的方法[11],该方法优化了一个噪声图像与目标样式和内容迭代地在预训练的VGG网络的帮助下•灵活且快速的任意风格 - 每模型方法,其可以实现任意样式传输而不需要再训练。在这项研究中,我们与以下三种方法进行比较:-Patch-based [8]:基于补丁的方法通过交换每个内容特征补丁与最近的样式补丁来进行样式传输。网络由卷积网络,反向网络和样式交换层组成。-AdaIn [12]:AdaIn基于自适应实例规范化,AdaIn网络由编码器,解码器和自适应实例规范化层组成,其中编码器被固定为VGG-19的前几层.-通用[16]:通用是基于在一系列预编码的编码器 - 解码器图像重建网络中嵌入的白化和着色变换而设计的。在在基线方法上方,TextureNet在传输质量方面比其他四种基线方法更令人印象深刻,因此我们将其作为基准。这些基准方法的结果都是通过使用默认配置运行其发布的代码而获得的。
人工智能之(重磅)微软提出字符字体转换和神经风格转换的统一框架结论和未来工作:在本文中,我们提出了一种用于字符字体转换和神经风格转换的统一样式转换框架EMD,它使得转换模型可以推广到新的风格和内容,给出一些参考图像。主要思想是,从这些参考图像中,风格编码器和内容编码器分别提取风格和内容表示。然后,提取的样式和内容表示由混音器混合并最终馈送到解码器以生成具有目标样式和内容的图像。这种学习框架允许在多种风格之间同时传递样式,并且可以被视为一种特殊的“多任务”学习场景。然后将学习到的编码器,混音器和解码器作为共享知识,传递神经风格的转移任务。这两项任务的广泛实验结果证明了它的有效性。
在我们的研究中,学习过程由一系列图像生成任务组成,我们试图通过学习高层次的策略来学习一种能够推广到新的但相关的任务的模型,即学习风格和内容表示。这类似于“学习学习”计划。未来,我们将探讨更多关于“学习学习”并将其与我们的框架相结合
