跳出微软研究院心向产品化, 她如何推动无监督学习反欺诈技术的应用?
时间:2018-01-25 来源:互联网 浏览量:
技术的深度应用在给人类带来“光”的同时,也有“暗”在生长。科技风险已成为各行业主要的风险之一,从电信诈骗,到钓鱼木马、买卖个人信息,再到如今有组织的羊毛党,欺诈者一直在开拓攻击手段和领域,这也要求着安全和风险分析技术的更迭换代。
近年来不断发展的大数据与人工智能技术,逐渐成为风控与反欺诈从业者的有力武器。成立四年的DataVisor打出“无监督学习算法”这一旗帜,再结合监督学习、自动规则引擎,为客户提供多应用场景的保护,包括大量虚假账户注册、账号盗取、欺诈交易、身份盗用、洗钱交易、假冒评估、垃圾邮件、虚假安装推广等。

创始人、CEO Yinglian Xie (谢映莲) 毕业于卡内基梅隆大学计算机系并取得博士学位,有超过十年的安全领域行业经验,一直致力于打击大规模网络线上攻击,此前任职微软硅谷研究院。近日,她与进行了一次深入的访谈。
三大技术构建护城河
“人工智能产业发展有四个维度:场景、大数据、计算能力与算法。大数据是基础,计算能力是前提,算法靠人才。在细分场景已经确定的前提下,大数据非常重要。而这部分需要行业顶级专家的深度参与,通过大数据的清洗、标签,把行业顶级专家的知识转移给机器,从而让人工智能站在巨人的肩膀之上。”清华教授邓志东告诉。
在现实中,各行业或许拥有较多的数据积累,但带标签的数据却很少,需要依赖行业顶级专家的深度参与,人力限制是一方面,另一方面是有标签的数据较难得,拿到之后通常也存在滞后效应,无法检测新型的未知类型的攻击。而标签数据的及时性和准确性,直接影响模型的效果。无监督学习已经无法满足现状,从业者开始应用无监督学习来应对这种情况。
顾名思义,无监督学习可以不依赖于标签和训练数据,自动挖掘新攻击。当攻击快速变化时,也能自动继续跟踪挖掘。“它最大的好处是,化‘被动跟着敌人跑’,为‘在攻击发生之前或同时做出反应’”,谢映莲说,并且还能检测潜伏期账户,起到提前预警作用。
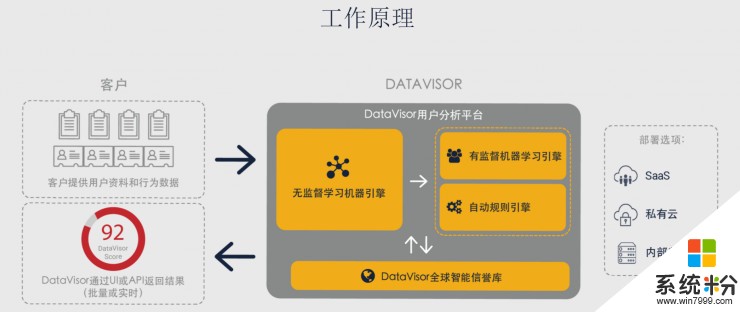
据介绍,DataVisor一般通过挖掘平台用户的三类数据:账户注册信息、行为信息以及其他信息(IP、地理位置、设备等)。“下一步,把该平台一段时间内进行同一行为的用户放在一起来检测,聚类分析,发现账号间的相似性和相关性,形成单个用户画像。”比如,当一个新用户注册时,平台无法获知更多信息,但是联系所有用户时,可能有一些用户使用非常相同或相似的头像、名字、手机型号等,行为就凸显出来了。
谢映莲告诉,目前无监督机器学习在实际应用中比较少,难度是在于如何设计算法、体系架构以及保障算法的效果。
另一个也在无监督学习体系下的技术是自动规则引擎。传统规则引擎都是人工调试,DataVisor在此基础上利用机器学习技术,挖掘出了很多欺诈群组,而每个群组都有一条或者多条规则,那么如何将这些结果转化成人类可以理解的规则,以满足监管或者其他需求呢?
据称,他们会总结规则的相似性,并用统计原理对规则的生成进行严格的测试,从而使之既有解释性,又能满足平台的需求。
“总的来说,这三种技术有着不同的作用,形成互补。有监督学习在有标签的情况下,能够挖掘出有规律的特征,与无监督学习可以结合利用。而自动规则引擎主要就是满足解释性需求,并且减少人工调试的繁琐和错误率。”
此外,他们还打造了DataVisor 全球智能信誉库,为上述技术提供数据支持。主要通过挖掘、整合攻击信号,并进行二度计算,提炼出更具有代表性的信号。据称,数据库拥有来自不同领域超过20亿用户的欺诈行为数据,如IP地址、UA信息、邮箱域名、设备类型等。
基于以上三种技术加全球智能信誉库,他们开发了用户分析平台。由于该平台本身就具有通用和可延展性,所以能够与不同的数据、不同的使用场景挂钩对接,也就出现了八大应用场景。
进入中国,发力金融
那么在实际应用,DataVisor是如何结合应用场景,为客户提供服务的呢?
谢映莲表示,第一阶段非常重要的工作就是帮助客户梳理和清洗数据,数据的质量与算法的好坏也是密不可分。虽然DataVisor会面临数据全面与准确性的挑战,但她也指出,各机构关于数据的意识已经比较强烈,“会有一些(数据梳理)基础,虽然参差不齐。”
下一步是理解客户的业务场景和需求痛点,“将我们的算法和对方数据相结合,帮助客户解决实际问题。”上述完成后,需要对相当于技术框架和产品进行调试,根据客户反馈进行一到两次调优,然后进入产品上线阶段。
客户可以通过DataVisor用户界面、用户分析控制台获取检测结果,或者通过DataVisor结果API批量导出或实时传送检测结果,或者直接购买规则自行建册。根据客户不同的业务需求,DataVisor数据分析平台提供多种类型部署选项,包括内部部署、SaaS服务和私有云部署。
据称,DataVisor的客户有如美国最大点评网站Yelp、Pinterest,以及财富500强金融机构等。2016年11月,正式进入中国市场后,在国内建立合作的公司包括大众点评、猎豹移动、今日头条等。
DataVisor还表示下一步将会发力金融行业。据谢映莲介绍,当前与金融机构的合作主要集中在账号保护、信贷申请、交易结算和反洗钱方面。以前述财富500强公司为例,该公司在超过200个国家提供服务并且已经进入金融服务行业超过100年,DataVisor主要为其提供反交易欺诈服务。该欺诈与风险策略总监能够在欺诈者发起攻击前数天或数小时检测到他们,使欺诈交易损失减少超过30%。
另外,美国最大的商家结算支付平台在采用DataVisor一站式风险数据分析平台后,实时阻止了17%的交易纠纷欺诈,每年平均为平台商户节省超过5万美元。
而说到国内风控市场,俨然一片红海,相关技术提供商已经不胜枚举,漂洋过海的DataVisor如何在竞争中占据一席之地?
“市场广阔,难免会有竞争,但我认为这会是良性竞争”,谢映莲持着乐观的观点,“市场不同的参与者会起到不同的作用,有些专做白黑名单、识别指纹这些信号类型的工作,有些像我们提供算法和平台,都是在完善生态系统。”
她表示,内部有很多华人工程师,中国也是公司未来的战略重点,并透露了DataVisor国内发展计划。首先,会继续提高无监督机器学习技术的智能化,使之能匹配适用更广泛的场景,减少人工干预。其次,根据客户需求,进行本地化调整,比如说,对中文语言文字处理的优化;另一方面,国内有较多羊毛党、刷机行为,规模性更强,会考虑中国的攻击特点进行调整。
心向技术产品化
“经过微软的多年经验,意识到无监督学习的重要性,大家觉得以前的方法是‘头痛医头,脚痛医脚’,而透过互联网上支付、刷单行为,我们看到本质其实是账号层面的欺诈。所以我们诞生一个想法——解决账号生命周期中存在的各种欺诈。”
谢映莲向描述其立项创业的心路。她表示,微软研究院有很好的研究氛围,但是对个人来讲,并不满足于通过和微软各个部门合作进行的局部创新。其中的“她们”还包括联合创始人兼CTO俞舫,同样来自微软硅谷研究院。
“反欺诈行业一个特点是,对手在不断变化,问题不是静止的。我们在不停地追求新技术应对攻击,另一边又在将这种技术能力产品化,两个过程都充满着挑战性,也让我非常兴奋。”
这些或可总结为支持她过去十年以及未来可能的数十年,从事该行业的动力。
