如何识别AI中的歧视? 微软列举了5点
时间:2017-09-29 来源:互联网 浏览量:
AI会成为种族主义者吗?好吧,这得看情况。假设你是一名在学校读书的非裔美国人,在该学校要使用面部识别软件进入大楼和访问在线家庭作业。这时候软件出了一个问题:学校此前只用浅肤色测试了软件算法。你肤色有些黑,因此软件在识别你时经常有问题。
你有时会迟到,有时甚至不能按时完成作业,使得你成绩不好。这一结果就是仅因肤色导致的歧视。虽然这不是真实案例,但类似的AI失策在科技业和社交圈已经声名狼藉。行业对AI兴奋的理由很充分——大数据和机器学习带来了几年以前无法想象的强大体验。

但对AI而言,要实现承诺就要保证,系统必须是可信的。人们的信任感越强,与系统交互次数也就越多,系统也就能使用更多数据来给出更好的结果。但信任需要花费很长时间来培养,偏见却可以瞬间摧毁它,并给社区造成真正的伤害。
认识AI中的排外
在微软,工作人员开发了包容性的设计工具和流程,从而能在设计流程识别残障人士。通过实践进化,微软将这种设计思维扩展到了其他排外领域,包括认知问题,学习方式偏好和社会歧视。对AI而言,现在是时候采用同样的方法了。

如果建立(系统)之初没意识到包容性,AI偏见就会发生。创建包容性AI最重要的步骤是,认识到偏见在哪儿,以及如何影响系统。包容性设计的第一个原则就是认识到排外。本文的介绍指南将AI偏见分解成不同类别,因此产品创造者能在早期发现问题,预测未来的问题,并在途中做出更好决定。通过让团队清晰看到系统在哪儿出错,能帮助他们识别偏见(identify bias),并建立兑现AI对所有人承诺的体验。
识别偏见的五种方式
通过与学术和行业思想领袖共同合作,微软确认了5种方式来识别偏见。然后,微软用童年情景作为隐喻来说明每个类别中的行为。为什么要这样做呢?我们可以将童年经历和偏见联系起来,并且与这个比喻很贴切:AI还在起步阶段,就像儿童那样,它的成长反映了我们如何培养和养育它。

通过首先解决这5种偏见,能创造更多包容性产品
每一个偏见分类(分解图如上)都包括了一个童年隐喻,包括定义,产品案例,以及团队和AI工作要面临的压力测试。
数据偏见
儿童会纯粹地依据能看到的少量(世界)来定义世界。最终,孩子们会学习到,大部分世界超越了他们视野范围能看到的少量信息。 这是数据偏差的根源:AI依赖的信息太小了,或者说太同质。

定义:给机器学习模型训练用的数据不能代表客户群的多样性。大规模数据集是AI的基础。同时,数据集会被缩减成没考虑各种用户的概述,无法真实地反映他们。
产品案例:机器视觉技术——如跟踪用户动作的网络摄像头——只适用于基于种族的小群用户(主要是白种人),因为最初的训练数据排除了其他种族和肤色。
压力测试:如果你正使用一个训练用数据集,那么这个样本包含你客户群的所有人吗?如果没有的话,你是否测试了未包含在样本中用户的使用结果?你AI团队中的人是否包容、多样和敏感,从而能识别偏见呢?
团体偏见
想象一下那些喜欢玩“医生游戏”的孩子。男孩想要扮演医生,并假定女孩会扮演护士。女孩必须自己来打破这一假设,“嘿,女孩也能当医生呀。”
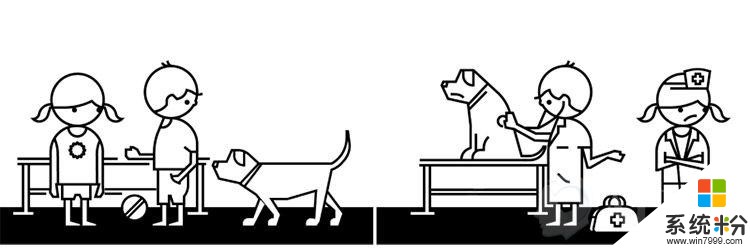
定义:训练AI模型的数据强化和增加了文化偏见。当训练AI算法时,人类偏见可对机器学习产生影响,保留这些偏见可能会在未来互动中导致不公平的客户体验。
产品案例:语言翻译工具会带来性别假设(如飞行员——pilot——是男士,空中服务员——flight attendant——是女士。
压力测试:你的结果是否让团队永久定型了性别或种族?为了打破不良和不公正的团体,你该做什么?你的数据集已经分类和标记了吗?
自动化偏见
想象一个要进行打扮的女孩。这个女孩喜欢运动,喜欢自然的外观,并讨厌任何人为的。但美容师对她的美丽有不同想法,给她用了许多化妆品,并设计了繁琐的发型。这个结果虽然让美容师开心了,却让女孩感到恐怖。
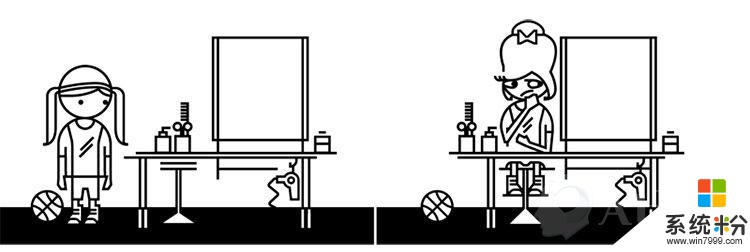
定义:自动决策超越了社会和文化因素。预测程序自动完成的目标可能违背人类多样化,这些算法并不是对人类负责,而是在人的影响下做出决定。AI设计师和从业者要考虑其系统对人们目标的影响。
产品案例:美化照片滤镜在面部图像上强化欧洲人的美容观念,如减轻皮肤色调。
压力测试:真正的,形形色色的顾客真地同意你算法给出的结论吗?AI系统是否拒绝人类决定,更倾向于自动化决定?你如何保证系统中有人的视角?
互动偏见
有个非常流行的儿童游戏“打电话”。团队中的第一个小朋友把一句话告诉下一位,然后这个人以同样方法传递给下一个,直到告诉最后一人,并说出他听到的话。这里的关键是观察经过多次自然传递后,信息会发生什么样的改变。但如果一个孩子故意改变它的话,会带来更荒唐的结果。虽然这可能会很有趣,但观察事情自然发生的愿望就破碎了。
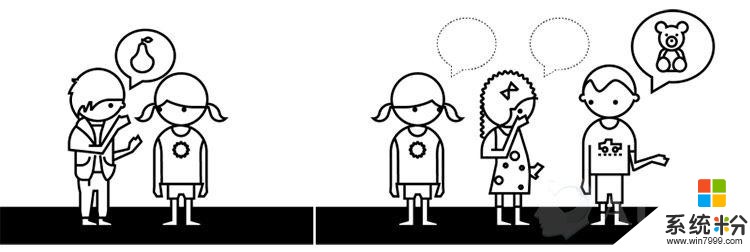
定义:人类篡改AI并产生有偏见的结果。现在的聊天机器人能讲笑话和愚弄人们,让人类认为它们是人。但许多尝试赋予AI人性的实验,都在无意间制造出被有毒人类偏见污染的电脑程序。当机器人在没有保护措施情况下开始广泛学习时,互动偏见就会出现。
产品案例:人类故意将种族或性别歧视的语言教给聊天机器人,让机器人开始说让人反感的东西。
压力测试:你有没有检查面向系统的恶意倾向?你的AI系统从人们那儿学了什么?你设计了实时交互和学习功能吗?AI反馈给客户的到底意味着什么?
证实偏见
想象一下收到玩具恐龙作礼物的小孩吧。其他家庭成员看到了这个恐龙,并送给了他更多恐龙。几年后,朋友和家庭成员假设他是一个恐龙爱好者,并持续不断给他更多恐龙,直到他拥有巨大收藏。
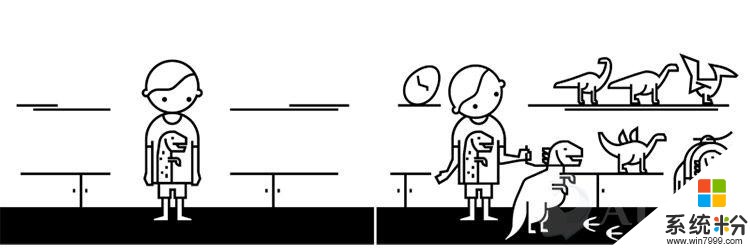
定义:过度简化个人特性会产生对一个群体或个人的偏见假设。证实偏见会倾向于寻找支持先入为主想法的信息。AI算法会提供匹配人们已经选择的内容,这排除了那些不受欢迎的选择。这不利于看到与个人想法对立的观点,阻止你看到不同想法和备选方案。
产品案例:购物网站推荐的东西经常是顾客已经买过的。
压力测试:你的算法是否建立在流行选项,强化了这些选择?随着时间推移,你的AI能依据用户改变做出动态演算吗?你的AI系统能让顾客以更多样和包容的视觉看世界吗?
未来还很长
以上是微软作为AI设计师和创造者的一些经验,涉及AI如何进化,以及AI如何影响真实的人。而这仅仅是漫漫长路的开始——一创造出这样一种体验,AI能平等服务所有人。

回到文章最初提到的非裔美国人例子,我们可以将其标记为数据偏见:因为这个面部识别软件使用的训练数据过于狭窄。如果一开始就能识别和理解这些偏见,我们就能在考虑别人想法的情况下测试系统,并创造更包容的体验。我们的面部识别软件是否受制于错误数据?又有哪些偏见会影响到使用体验呢?
许多AI领域工作的人都会遇到这种类似的轶事证据。但令人尴尬的是,无意的偏见会产生令人不快的结果,虽然这是我们希望识别和避免的。借助本文提到的方法,有助于帮助开发者认识可能导致上述状况的潜在偏见:以上述分类开始测试下你的经验,看思维中是否存在这些偏见,这能让你更好地专注于为所有客户提供AI的潜能。
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软改变主意在停止支持后为Windows7黑屏bug开发免费补丁
- 2 亚马逊和微软打磨最强AI语音助手: 试邀谷歌苹果合作
- 3 Windows 10新版给力功能上线:系统瞬间清爽了
- 4微软新款Surface笔记本终于公布! 售价定为999美元
- 5微软公布Windows10X核心功能:支持UWP/Win32/PWA应用
- 6微软推超级麻将AISuphx十段水平远超人类选手
- 7微软与V社合作 WindowsVR头显将支持SteamVR
- 8微软云也是黑客的“菜” 超过3500名工程师严阵以待
- 9微软:Windows 10创造收益将继续迅猛提升
- 10iPhone面世10年 苹果利润相当于微软与谷歌总和
