微软研究院开源DialoGPT:你有什么梦想?「让世界充满机器人」
时间:2019-11-20 来源:互联网 浏览量:
作者:Yizhe Zhang, Siqi Sun, Michel Galley等
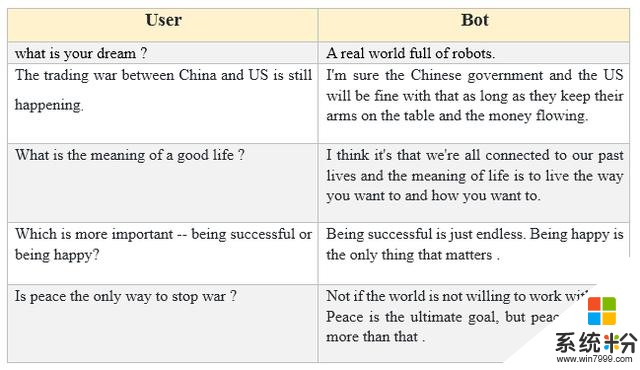
利用微软 DialoGPT 生成的对话结果示例。
DialoGPT 是一种用于对话响应生成的可调节式千兆词级神经网络模型,其训练基于 Reddit 数据。该研究成果的源代码已经开源,另外他们也发布了一个大规模预训练模型。
论文:https://arxiv.org/abs/1911.00536项目:https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/代码:https://github.com/microsoft/DialoGPT近来,使用基于 transformer 的架构进行大规模预训练方面进展颇丰(Radford et al., 2018; Devlin et al., 2019; Raffel et al., 2019),这些进展也在实践中取得了巨大的成功。举个例子,OpenAI 的 GPT-2(Radford et al., 2018)表明在大型数据集上训练的 transformer 模型能够捕获文本数据中的长程依赖性,进而生成流畅、词法多样以及内容丰富的文本。这样的模型有能力习得细粒度的文本数据,并得到能近似模仿人类所写的真实世界文本的高分辨率输出。
DialoGPT 是对 GPT-2 的扩展,目标是解决对话神经响应生成中的挑战性难题。神经响应生成是文本生成的一个子类。而文本生成任务的目标都是生成与提示有关联的看起来自然的文本(同时又与任何训练实例都不同)。但是,建模对话面临着很多显著的难题,因为人类对话中两个参与者的目标可能是相互抵触的,而且可能响应的范围在本质上也更具多样性。因此,对话生成中的一对多问题通常比神经机器翻译、文本摘要和文本释义等其它文本生成任务的问题更为困难。人类对话通常更加不正式、噪声更多,而当以文本形式聊天时,通常还含有非正式的缩写或句法/词法错误。
类似于 GPT-2,DialoGPT 是以自回归语言模型的形式构建的,其模型架构使用了多层 transformer。但不同于 GPT-2,DialoGPT 的训练使用了从 Reddit 讨论链中提取出的大规模对话对/会话。作者猜想这应该能让 DialoGPT 学到对话流中更细粒度的 P(Target, Source) 的联合分布。他们在实践中也观察到了这一现象:DialoGPT 生成的句子丰富多样而且包含特定于源提示的信息,类似于 GPT-2 为连续文本生成的结果。
作者在一个公开的基准数据集(DSTC-7)和一个新的从 Reddit 帖子中提取出的 6k 大小的多参照测试数据集上对新提出的预训练模型进行了评估。结果表明,DialoGPT 在自动评估和人类评估方面都取得了当前最佳的表现,将对话生成结果的质量提升到了接近人类的水平。 作者已经公布了本研究的源代码与预训练模型。作者表示,这种模型使用简单,能够轻松地适应新的对话数据集,尤其是训练样本较少的数据集。这个 DialoGPT 软件包还包含一个开源的基于 Huggingface PyTorch transformer(HuggingFace, 2019)构建的训练工作流程(数据提取/准备和模型训练/评估)。
方法 模型架构 DialoGPT 模型基于 GPT-2 架构。它从 GPT-2 继承了带有层归一化的 12 到 24 层 transformer、一种适用于经过作者修改的模型深度的初始化方案,用于 token 化器的字节对编码(Sennrich et al., 2016)。遵照 OpenAI 的 GPT-2 方法,作者将多轮对话会话建模为了长文本,将生成任务纳入到了语言建模任务的框架中。 作者首先将一个对话会话中所有对话回合连接成一个长文本 x_1, · · · , x_N(N 为序列长度),并以「文本结束 token」结束。可将源句子(对话历史)记为 S = x_1, · · · , x_m,将目标句子(基本真值响应)记为 T = x_{m+1}, · · · , x_N,则 P(T|S) 的条件分布可以写为一系列条件概率的积:
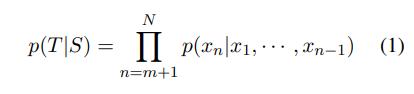
对于多轮对话实例 T_1, · · · , T_K,(1)式可写为 p(T_K, · · · , T_2|T_1),这本质上就是 p(T_i |T_1, · · · , T_{i−1}) 的条件概率的积。最终,对单个目标 p(T_K, · · · , T_2|T_1) 的优化可以被视为是优化所有的 p(T_i |T_1, · · · , T_{i−1}) 源-目标对。作者这里的实现基于开源的 PyTorch-transformer 库。
链接:https://github.com/huggingface/pytorch-transformers 互信息最大化 开放域文本生成模型有一个众所周知的困难,即会生成枯燥的、没有信息的样本。为了解决这个问题,作者实现了一个最大互信息(MMI)评分函数(Li et al., 2016a; Zhang et al., 2018)。MMI 是利用一个预训练的后向模型来预测给定响应的源句子,即 P(Source|target)。作者首先使用 top-K 采样生成一组假设,然后使用 P(Source|Hypothesis) 的概率来对所有假设重新排序。直观来看,最大化后向模型似然会对所有枯燥的假设施加惩罚,因为频繁的和重复性的假设可能与很多可能的查询有关,因此在任意特定查询下得到的概率会更低。 作者也尝试了使用策略梯度来优化奖励
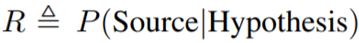
,其中与 Zhang et al. (2018) 一样使用了一种样本平均的基线。这个验证奖励可以得到稳定提升,但不同于 RNN 框架下的训练,作者观察到强化学习训练容易收敛到某个劣化的局部最优解,这时的假设仅仅是对源句子的重复(即学舌模式),此时的互信息是最大化的。作者猜想,由于 transformer 具有强大的模型表征能力,所以它们很容易陷入局部最优位置。但强化学习训练规范化的相关工作还有待未来研究。
结果 作者将 DialoGPT 与另外两个基准进行了比较:作者自己内部的基于 (Li et al., 2016a) 的序列到序列模型 PersonalityChat,这个模型是基于 Twitter 数据训练的,已经在微软 Azure 的 Cognitive Service 得到了实际应用。表 2 总结了自动化评估的结果。有 345M 个参数的 DialoGPT 以及波束搜索在几乎所有基准上都得到了最高的自动评估分数。
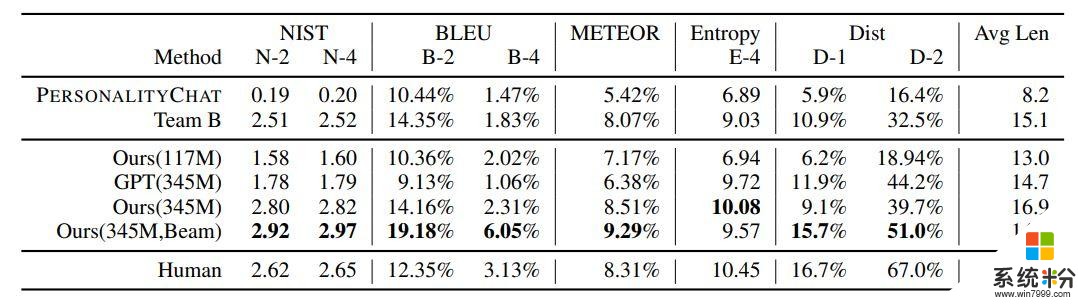
表 2:DSTC 评估
作者进一步在一个有 6K 个样本的多参照测试集上评估了 DialoGPT。结果见表 3。测试过程使用了两种设置:从头开始训练以及使用 GPT-2 作为预训练模型进行微调。在这两种设置中,更大的模型都总是优于更小的模型。另外表 3 的倒数第二行总结了执行互信息最大化的结果。
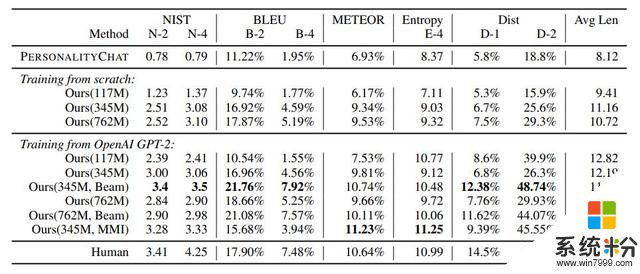
表 3:6K Reddit 多参照评估
表 4(交互式聊天)和表 5(有用户提示的自播放聊天)给出了一些生成对话的样本。

表 4:解决常识问题

表 5:多轮对话的交互式示例
有趣的是,新提出的模型表现出了在一定程度上解决常识问题的能力,作者猜想这可能要归功于 Reddit 数据中可以学习到的丰富信息。在某些案例中,模型并不是给出「所需的」答案,而会生成另一个可替代的合理答案。作者观察到,该系统能比 RNN 对话生成系统更好地处理多轮对话生成,而且往往在上下文方面更能保持一致(表 5)。 作者还通过众包评估了从 Reddit 6K 测试数据集随机采样的 2000 个测试源。系统经过了配对,每一对系统的输出都被随机呈现给 3 位评判者,他们会根据相关性、信息量和生成结果与人类结果的相似程度使用一个 3 分制的类 Likert 度量对这些结果进行排名。作者先要求这些评判者经过了一个资格测试,并采用了一种垃圾检测制度。表 7 给出了评判者在相关性、信息量和人类相似度方面的整体偏好,结果用原始数值与占整体的百分比来表示。
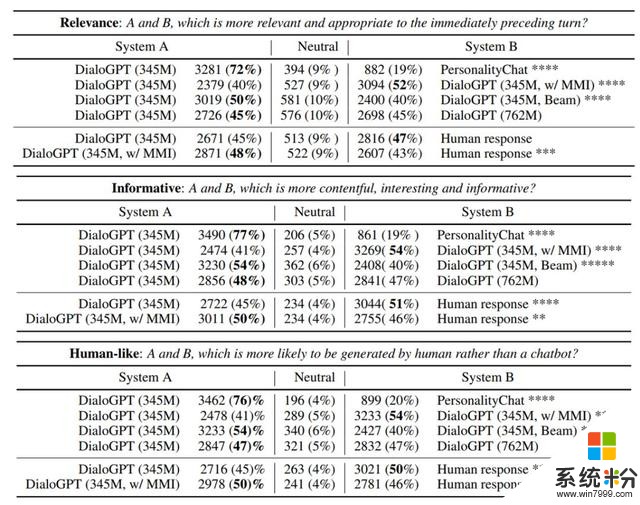
表 7:在相关性、信息量和人类响应可能性方面的人类评估结果
表 7 还表明「单纯」的 DialoGPT 基质模型可能就已经能达到与人类响应相近的质量了。
相关资讯
- 沈向洋:微软研究院——求索不已,为全人类,打造负责任的AI
- 微软研究院:智能扬声器超声波束可生成房间图像
- 微软又开源了一个ML框架,这次是核心产品机器学习引擎infer.NET
- 18日热点新闻:微软宣布TextWorld开源:基于Python
- 微软宣布TextWorld开源项目:基于Python,可生成文本游戏
- 微软研究院发布开放数据项目,公开 15 类内部研究数据集
- 微软内部研究数据集正式对外开放,覆盖NLP、CV等9个领域
- 腾讯回应微软研究院首席研究员张正友加盟:欢迎业界最顶尖人才加入
- 自动驾驶1月29日汇总——微软推开源自动驾驶仿真平台 AirSim教程
- 微软研究院正开发人工智能绘图机器人:想画啥,尽管说










最新热门游戏
-
10卡车之星新春版本










微软资讯推荐
- 1 微软真没骗人:外媒对比测试攒出Xbox One X性能的PC价格
- 2 微软IE3.0蓝影增强版开箱图赏: 16年传奇回忆
- 3 为迎接LGBT骄傲月 微软在Skype推出新表情与贴纸
- 4强力吐槽WIN10输入法bug电脑一重启,win10系统网页搜索框中,打字,就没有输入法词语提示了,只能盲打,找不到候选字词提示框。[抓狂][抓狂][抓狂]强迫症犯了,试了好多方法,终于解决了。分享给大家!一般情况是两种:1、原因是输入法出现了问题,还原输入法。按windows+i,
- 5鲜为人知的三个win10小技巧
- 6外媒:Twitter PWA展示了Windows 10应用的未来
- 7微软重大升级: Xbox One全系将支持1080P视频录制
- 8彻底禁止win10自动更新,用这款软件告别windows频繁弹出升级框
- 9硬蛋联合微软、全志发布人工智能 K-系统
- 10Windows10重磅更新翻车!微软不能忍了
